
One of the most promising advancements in artificial intelligence is Retrieval-Augmented Generation (RAG), a technology that is revolutionizing our interactions with technology. In this technique, Large Language Models (LLMs) are combined with powerful retrieval systems that fetch relevant information before generating responses to enhance their capabilities.
A high-performance, efficient RAG system can be run locally by developers without relying on cloud services with Ollama and DeepSeek R1. We will walk you through the basics of Ollama and DeepSeek R1 in this comprehensive guide, as well as how to set them up locally and integrate them into a RAG system that supports AI-powered applications.
Why Use Ollama and DeepSeek R1?
Ollama: Simplifying LLM Execution
It permits users to pull, run, and manage AI models with minimal setup. One of Ollama’s biggest benefits is that it automates the process of running LLMs locally.
- Local Execution: Data privacy does not require cloud-based APIs.
- Simplified Model Management: Models can be easily downloaded and switched between.
- Optimized Performance: The design is optimized for efficient execution on consumer hardware.
Ollama DeepSeek R1 : A Cutting-Edge Open-Source Model
With DeepSeek R1, an advanced open-source AI model able to support reasoning, retrieval, and text generation, it is designed to compete with high-end proprietary models. There are many advantages to Ollama DeepSeek R1 including:
- Strong Retrieval Capabilities: The perfect solution for RAG systems that need external data fetched.
- Optimized for Reasoning: Provides effective answers to complex queries.
- Open-Source & Flexible: The system can be fine-tuned and customized.
Using Ollama and DeepSeek R1 together, you can create a highly efficient RAG configuration entirely on your local computer.
Step 1: Installing Ollama
It is necessary to install Ollama before installing DeepSeek R1. The installation process differs depending on your operating system.
Installing Ollama on macOS
You can install Ollama via Homebrew on macOS:

brew install ollama
You can also download the installation package from the Ollama website and follow the steps to set up the software.
Installing Ollama on Linux
There is an installation script provided by Ollama for Linux users:

Before running this command, make sure you have curl installed.
Installing Ollama on Windows
Currently, Ollama doesn’t support Windows, but you can run it using Windows Subsystem for Linux (WSL). If you haven’t set it up already, use the following instructions:

Once WSL is installed, follow the Linux installation steps.
Verifying Installation
Once Ollama has been installed, you can verify that it has been correctly configured by running the following commands:

Ollama’s installed version will be returned by this command if the installation was successful.
Step 2: Downloading & Running DeepSeek R1
Ollama can now be installed and DeepSeek R1 can be downloaded.
Pulling the DeepSeek R1 Model
The following command should be run in your terminal:

You will need to ensure that you have sufficient storage and a stable internet connection in order to execute this command. The download size may be large, so you should have sufficient storage and a stable internet connection.
Running DeepSeek R1 Locally
Execute the following commands once the model has been downloaded:

By executing this command, DeepSeek R1 will be initialized and you can start interacting with it through the command line. Now you can enter prompts and AI will respond to those prompts.
Step 3: Implementing RAG with DeepSeek R1
The Retrieval-Augmented Generation (RAG) system works by searching for relevant documents and supplying them before generating a response. This approach increases the accuracy and relevance of AI.
Setting Up a Basic RAG Pipeline
DeepSeek R1 must be integrated into a RAG pipeline as follows:
- A knowledge base can be used to retrieve relevant documents.
- Provide the context of the retrieved content to DeepSeek R1.
- Provide a response based both on the query and the information that was retrieved.
Installing Required Dependencies
RAG can be implemented in Python by installing the following packages:

Python Script for RAG
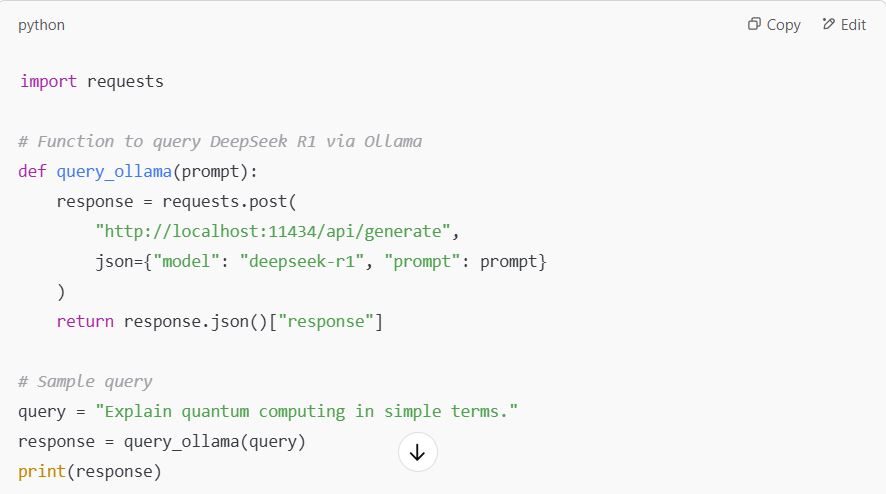
Step 4: Optimizing Performance
LLMs require a significant amount of computing power to run locally. Here are some tips on improving performance:
1. Enable GPU Acceleration
NVIDIA GPUs can speed up DeepSeek R1 using CUDA. To check whether CUDA is enabled, run the following command:

You can enable GPU acceleration in Ollama if your system supports CUDA.
2. Use Model Quantization
In Ollama, models can be quantized (e.g., INT8) to reduce the amount of hardware required. The reduction of precision can improve efficiency and save memory.
3. Optimize the Retrieval Pipeline
Consider vector databases like ChromaDB or FAISS for large datasets to speed up search. Pre-indexing documents can also significantly improve performance.
Step 5: Expanding the System
1. Building a RAG-Powered Chatbot
It is possible to build a conversational AI assistant by integrating DeepSeek R1 with a chatbot framework (e.g., FastAPI or Flask) that dynamically retrieves and generates responses based on input from the user.
2. Fine-Tuning Ollama DeepSeek R1
Using domain-specific data can improve the performance of DeepSeek R1 if your task requires a model tailored to specific requirements.
3. Deploying a Web-Based RAG System
DeepSeek R1 supports Next.js, React, and Vue.js integrations to make your RAG system accessible through a web interface.
Conclusion
In this guide, you learned how to install and configure Ollama and DeepSeek R1 on your local computer, and how to build a basic RAG system.
- Due to the fact that everything runs locally, there is enhanced privacy.
- The use of external APIs has been reduced, which has improved efficiency.
- The ability to develop AI-powered applications on a large scale.
It is possible to build highly intelligent AI assistants, research tools, and automated knowledge systems by accelerating GPUs, fine-tuning the retrieval pipeline, and optimizing the retrieval algorithm.
Do you want to know more about how RAG can be integrated into a production system? Let us know in the comments!
Frequently Asked Questions (FAQs)
1. What is Ollama, and why should I use it?
The Owlama framework simplifies the process of managing, executing, and optimizing Large Language Models (LLMs) on a local system, making it easier to run AI models in a cloud-free environment.
Key benefits:
- Ensures privacy and security by running models locally.
- Performance-optimized for consumer hardware.
- Provides support for a variety of LLMs, including DeepSeek R1, Llama, and Mistral.
2. What is DeepSeek R1, and how does it compare to other models?
The DeepSeek R1 model is an open-source machine learning model designed to perform reasoning and retrieval-based tasks. It competes with models like GPT-4 and Llama 2, but is optimized for RAG.
Key advantages:
- Designed for retrieval-enhanced tasks, making it ideal for answering questions.
- The software is open-source and can be customized.
- The system can be fine-tuned to suit specific needs.
3. How do I install Ollama?
You can install Ollama based on your operating system by following these steps:
- Olllama can be installed on Macs using brew
Linux:
curl -fsSL https://ollama.ai/install.sh
- The Windows installation steps are the same as those for the Linux installation, but you’ll need to install Windows Subsystem for Linux (WSL).
Verify installation using:
ollama –version
4. How do I download and run DeepSeek R1?
Run the following command after installing Ollama to download DeepSeek R1:
ollama pull deepseek/deepseek-r1
Use the following commands to start the model locally:
ollama run deepseek-r1
By using this method, you can either interact with the model using your terminal or integrate it into a Python script.
5. What hardware do I need to run DeepSeek R1 locally?
The DeepSeek R1 software consumes significant resources, especially when modeling large datasets.
Minimum requirements:
- CPU: 8-core processor (Intel i7/AMD Ryzen 7 or better)
- RAM: At least 16GB (32GB+ recommended for smooth performance)
- Storage: ~20GB free disk space (for model storage)
For GPU acceleration:
- NVIDIA GPU with CUDA support (RTX 3080 or better recommended)
- Install CUDA Toolkit and cuDNN for improved performance